Basis Function Alignment
Interpreting Basis Function Alignment Output
In this analysis, your data will be compared to patterns of multiple attributes potentially involving high, low, and medium levels of those attributes across team members. To do this, your data will be transferred to the radial plot below. A plot will be made for each pair of attributes in your data (e.g., if you have 3 attributes, AB, AC, and BC plots will be created). These plots are also summed to assess patterns across all attributes.
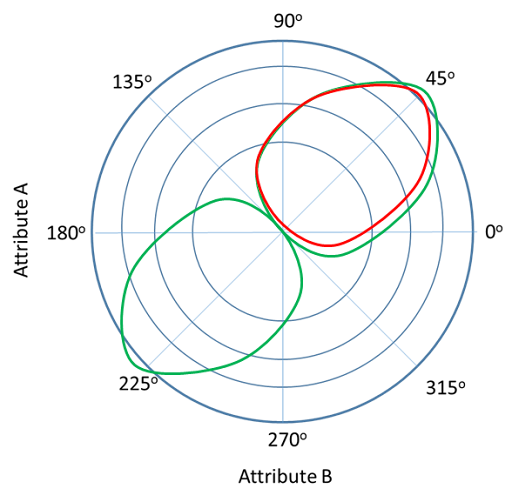
The midpoint of this graph will be the average score on that attribute across your sample. Thus if we test the red shape in this figure the output will be the degree to which that team (i.e., higher-level unit) fits a shape in which all members (i.e., lower-level units) are above average on all attributes. The green shape will indicate the degree to which the higher-level unit is comprised of lower-level units with attributes that agree – when one is higher the other is high, etc.
If you choose UpDown the program will output all shapes that involve high and low levels of the attributes. This will result in 2^4 or 16 shapes
If you choose UpMidDown the program will output all shapes that involve high, low, and mid levels of the attributes. This will result in 3^4 or 81 shapes. This may take up to 15 minutes to run.
Many of these shapes will be difficult to theoretically interpret. The “Sym” options will only produce 2, 4, 6, 8, 10, or 12 shapes that are symmetric and thus easily interpretable. Because these produce so few shapes, this analysis will run more quickly.
Important: The output will give you columns titled with four numbers that are either -1, 1, or 0. A ‘1’ indicates the pattern fully includes that quadrant. A ‘-1’ indicates that the pattern does not include that quadrant. A ‘0’ indicates that a quadrant includes a moderate level of that quadrant. To interpret the four-quadrant set, begin in the upper-right quadrant and go around the space counterclockwise. For example, the red shape in the figure has a pattern of [1,-1,-1,-1] because it only looks at a pattern that involves the upper right quadrant and is looking for strong representation within it. The green shape has a pattern of [1,-1,1,-1].
Again, the output will provide you a .csv file with a higher-level unit in each row and the strength that unit represents each pattern in columns labeled with the attribute included and their four-digit map, e.g., [-1,1,-1,0].
Data Formatting Note
Please format your data such that each lower level unit (e.g., team member) has its own row, and an identifier for the higher level unit it is nested within indicated in a separate column (e.g., TeamID). In this way, for example, a team of four members may be organized as follows:
As shown, each attribute of interest should also have a unique column and vary at the lower-level (e.g., individual-level). See "test_data.csv" for an example of how to structure your data for this analysis. When running attribute alignment analysis, also be sure you have no missing data in your file. Malformed rows for a team member (missing data, negative values) will cause the entire team to be ignored in the analysis. See resulting CSV for all teams that were considered in the analysis.